Il n'y pas si longtemps, quand on ouvrait un ordinateur, on pouvait voir que
la dite machine possédait un unique processeur. Sur ce type de machine (machine
de type Von Neumann ou machine séquentielle), le processeur
exécutait pas à pas une série d'instructions afin de sortir un résultat.9.1 Aujourd'hui les choses sont en train de changer, le nombre de processeurs par
machine augmente. Il est temps de penser parallèle, c'est à dire produire le
même résultats en utilisant ces multiples processeurs. De manière idéale, on
pourrait croire que le fait d'utiliser ![]() processeurs va réduire le temps
d'exécution d'un facteur
processeurs va réduire le temps
d'exécution d'un facteur ![]() . Malheureusement, Il s'agit d'une limite théorique
car les processeurs doivent communiquer entre eux et se synchroniser afin de
fournir le bon résultat (Overhead). Penser parallèle,
cela consiste déjà à diviser le travail de manière à exploiter au mieux les
processeurs. En général, on s'arrange pour répartir équitablement la charge
de travail (load balance), car on veut que les processeurs
passent la majeure partie de leur temps à travailler, et non à attendre ou communiquer
avec les autres processeurs.
. Malheureusement, Il s'agit d'une limite théorique
car les processeurs doivent communiquer entre eux et se synchroniser afin de
fournir le bon résultat (Overhead). Penser parallèle,
cela consiste déjà à diviser le travail de manière à exploiter au mieux les
processeurs. En général, on s'arrange pour répartir équitablement la charge
de travail (load balance), car on veut que les processeurs
passent la majeure partie de leur temps à travailler, et non à attendre ou communiquer
avec les autres processeurs.
Si, jusqu'à présent, on parlait peu parallélisme, c'est parce qu'il n'existait pas de langage standard, indépendant de la machine (portable). Parler de parallélisme indépendant de l'architecture matérielle peut être considéré par certains comme une hérésie. Toutefois, le Fortran 90 (ou Fortran 95) tend à s'imposer et dispose de nombreux optimiseurs sur différentes plateformes. Certes, ce n'est pas le Langage Parallèle par excellence, mais c'est le seul langage standard, disponible sur de nombreuses plateformes, et surtout il est présent sur le CRAY. Quoiqu'il en soit avant de parler d'optimisation, il est toujours nécessaire de connaître un minimum sur l'architecture de sa machine.
Le supercalculateur CRAY dont dispose le centre appartient à la série des J90 (Jedi). Ce système possède l'architecture des systèmes vectoriels CRAY. De plus, il comporte actuellement 4 modules de 4 processeurs, portant le nombre de processeurs à 16.
Chacun des processeurs (central processing unit: CPU) comprend des registres, des unités fonctionnelles ainsi qu'une section de contrôle qui assure la coordination entre les différents modes de fonctionnement. La fréquence d'horloge de chaque CPU est de 100 Mhz, ce qui donne une performance crête de 100 MIPS (Millions instruction per second) sur un code scalaire. Chaque CPU disposent d'unités fonctionnelles pouvant effectuer des opérations scalaires ou vectorielles en même temps. Chaque processeur peut fournir 2 résultats d'opération par période d'horloge. Grâce à cette architecture, la puissance en crête atteint 200 MégaFlops (Nombre d'opérations sur des réels flottants par seconde). L'architecture vectorielle du CRAY lui confère sa puissance.
Les entrées/sorties, la mémoire centrale, et l'horloge sont partagées par l'ensemble des processeurs et constituent donc des ressources partagées. Le CRAY J916 est donc typiquement une machine à mémoire partagée. Il y a évidemment une section commune à tous les processeurs destinée à gérer les communications entre les processeurs.
La plupart des problèmes nécessitant l'emploi d'un supercalculateur traitent d'un volume de données important et font donc de nombreux accès à la mémoire. L'efficacité ne dépend pas alors uniquement de la rapidité de calcul mais de la bande passante de la mémoire. En effet, il se peut que les données n'arrivent pas assez vite par rapport à la vitesse à laquelle elle peuvent être traitées. Les performances en sont donc diminuées. Pour le CRAY, la mémoire est partagée. Tous les processeurs peuvent accéder à n'importe quel mot de la mémoire. Le débit maximal est de 32 mots mémoires par période d'horloge. Cependant, il y a des limitations dans la façon d'accéder à la mémoire. Le CRAY utilise des composants de stockage de type CMOS dynamic random memory acces (DRAM) dont le temps d'accès est de 70 ns (7 périodes d'horloge).
La mémoire centrale est de 1,024 Go et est découpée en 8 sections. Il y a au total 256 bancs de mémoire (soit 32 par section). Il existe une forte contrainte sur ces bancs, on ne peut y accéder que tous les 140 ns. Chaque module de 4 processeurs possède 8 chemins indépendants (1 pour chaque section de la mémoire). Ceci interdit des références à une même section de la part de processeurs d'un même module, puisqu'ils partagent le même chemin physique. Une représentation schématique du CRAY présent à CYCERON est donnée Fig.10.1.
La parallélisation en Fortran 90 passe par l'utilisation
de tableaux de données. Une série de procédures intrinsèques, optimisées pour
la machine utilisée, sont disponibles et nous permettent de travailler efficacement
sur ces tableaux. Supposons, pour l'exemple, que nous disposions de matrices
bidimensionnelles ![]() (des images !) et que nous voulions effectuer
la somme de
(des images !) et que nous voulions effectuer
la somme de ![]() avec
avec ![]() pour obtenir
pour obtenir ![]() , on pense évidemment
à écrire:
, on pense évidemment
à écrire:
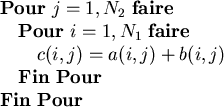
Ceci est parfaitement correct en Fortran 90, mais peut s'écrire simplement par
![]() . Arrêtons nous un instant sur la différence conceptuelle entre
ces deux formulations. Pour un programmeur (au sens large), il n'existe pas
de différence fondamentale, car il traduit naturellement l'expression de la
somme
. Arrêtons nous un instant sur la différence conceptuelle entre
ces deux formulations. Pour un programmeur (au sens large), il n'existe pas
de différence fondamentale, car il traduit naturellement l'expression de la
somme ![]() , en écrivant explicitement la somme pour tous les indices
ci-dessus. L'imbrication de deux boucles (l'ordre des boucles est fonction de
la façon sont rangées deux données consécutives en mémoire) est la manière naturelle
de traduire une somme sur des tableaux. Il s'agit là du lourd héritage des machines
séquentielles. En effet, pour ce genre de machine, on cherche toujours à décomposer
de manière séquentielle le problème. Il s'agit de lancer au processeur les instructions
une à une dans le temps. Pour penser parallèle il faut d'abord éviter de projeter
un problème dans le monde séquentiel ! La question que nous avons formulée initialement
consiste à sommer des tableaux et cette sommation ne conduit pas forcément à
effectuer chronologiquement la somme de leurs éléments. Pour penser parallèle,
il faut éviter de forcer le problème à devenir une suite chronologique (une
seule dimension temporelle) d'opérations élémentaires quand cette opération
se traduit naturellement de manière globale (notion de dimension spatiale des
données).
, en écrivant explicitement la somme pour tous les indices
ci-dessus. L'imbrication de deux boucles (l'ordre des boucles est fonction de
la façon sont rangées deux données consécutives en mémoire) est la manière naturelle
de traduire une somme sur des tableaux. Il s'agit là du lourd héritage des machines
séquentielles. En effet, pour ce genre de machine, on cherche toujours à décomposer
de manière séquentielle le problème. Il s'agit de lancer au processeur les instructions
une à une dans le temps. Pour penser parallèle il faut d'abord éviter de projeter
un problème dans le monde séquentiel ! La question que nous avons formulée initialement
consiste à sommer des tableaux et cette sommation ne conduit pas forcément à
effectuer chronologiquement la somme de leurs éléments. Pour penser parallèle,
il faut éviter de forcer le problème à devenir une suite chronologique (une
seule dimension temporelle) d'opérations élémentaires quand cette opération
se traduit naturellement de manière globale (notion de dimension spatiale des
données).
Le CRAY que nous utilisons est une machine parallèle à mémoire partagée possédant une architecture vectorielle. Pour optimiser un code écrit en Fortran 90 sur le CRAY, on peut jouer à deux niveaux: vectoriel et parallèle. Il faut, dans tous les cas, éviter tant que possible les conflits mémoires.
Le conflit mémoire survient quand un processus cherche à accéder successivement
au même banc mémoire. Rappelons qu'un accès mémoire rend le banc inaccessible
pendant un certain nombre de périodes d'horloge. De plus, en Fortran, Les éléments
successifs d'un tableau sont stockés dans des bancs mémoires différents. Par
exemple, pour les éléments d'un tableau ![]() , le premier élément
, le premier élément ![]() est stocké dans le banc
est stocké dans le banc ![]() , le deuxième élément
, le deuxième élément ![]() dans le banc
dans le banc
![]() , etc. Dans un programme, on doit faire attention à l'ordre dans lequel
on accède aux éléments d'un tableau, pour éviter que la lecture de deux éléments
successifs ne conduise à l'adressage d'un même banc. Si on prend le cas, d'un
tableau 2D, les éléments successif d'une même colonne sont stockés dans des
bancs mémoires séparés, tandis que les lignes appartiennent à un même banc.
Lors du parcours de ce tableau sous la forme de boucles imbriquées, il s'agit
de faire varier le premier indice le plus rapidement possible. Cela est valable
également pour des tableaux de dimension supérieure.
, etc. Dans un programme, on doit faire attention à l'ordre dans lequel
on accède aux éléments d'un tableau, pour éviter que la lecture de deux éléments
successifs ne conduise à l'adressage d'un même banc. Si on prend le cas, d'un
tableau 2D, les éléments successif d'une même colonne sont stockés dans des
bancs mémoires séparés, tandis que les lignes appartiennent à un même banc.
Lors du parcours de ce tableau sous la forme de boucles imbriquées, il s'agit
de faire varier le premier indice le plus rapidement possible. Cela est valable
également pour des tableaux de dimension supérieure.
La vectorisation correspond à une forme de parallélisme au niveau du processeur dans laquelle les éléments d'un tableau sont traités par groupes. Une boucle traitée de manière vectorielle peut être exécuté jusqu'à 10 fois plus rapidement qu'une exécution standard (traitement scalaire). Pour illustrer ce mode d'accélération, on peut le comparer à une chaîne d'assemblage industrielle [22]. Supposons que le but de la chaîne soit la confection d'une chaise dont la fabrication se fait en 5 étapes nécessitant chacune 1 minute.
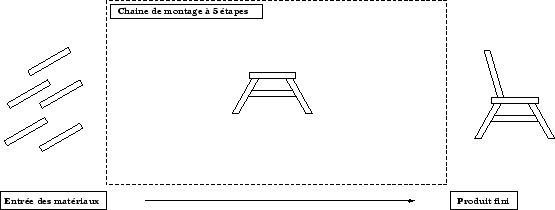
|
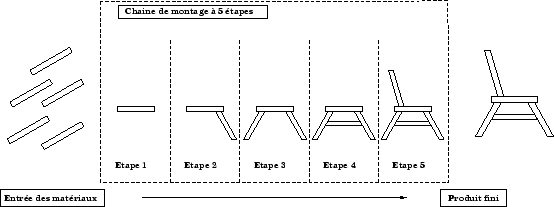
|

Pour vectoriser, les tableaux ![]() vont être chargés en mémoire.
Puis l'ensemble du traitement se fait, de façon à ne pas effectuer à chaque
itération un adressage mémoire. Dans l'exemple servant d'illustration, nous
avons deux boucles qui ne sont vectorisables qu'après réécriture par le compilateur
de deux boucles séparées.
vont être chargés en mémoire.
Puis l'ensemble du traitement se fait, de façon à ne pas effectuer à chaque
itération un adressage mémoire. Dans l'exemple servant d'illustration, nous
avons deux boucles qui ne sont vectorisables qu'après réécriture par le compilateur
de deux boucles séparées.

D'une manière générale, toutes les boucles sont candidates à la vectorisation. De plus, dans un série de boucles imbriquées, c'est la boucle la plus interne que le compilateur cherchera à vectoriser. L'utilisateur peut spécifier par l'emploi d'une directive de compilation9.2, la boucle qui lui semble la plus appropriée à la vectorisation.
Les conditions qui empêchent une boucle d'être vectorisée sont les suivantes:
Même en restant dans l'idée de faire exécuter une partie d'un même programme par plusieurs processeurs (Multitâches), il faut encore faire la distinction entre la parallélisation Macrotâche et la parallélisation Autotâche.
Dans le premier cas, on va essayer de distribuer une procédure écrite par l'utilisateur sur de multiples processeurs (forte granularité). C'est le programmeur qui fait l'analyse des dépendances.
Dans le deuxième cas, la parralélisation intervient sur de plus petites parties du programme, notamment sur les boucles (granularité plus faible). Elle peut se faire de manière automatique, ou peut être ajustée par l'utilisation de directives de compilation (Microtâche). Les boucles, parallélisées de manière automatique par le compilateur, sont importantes car elles contribuent fortement au parallélisme d'un programme. L'autoexécution (parallélisation autotâche des boucles principalement) prend un programme et le transforme, de manière automatique, en un autre s'effectuant simultanément sur plusieurs processeurs à la fois.
Quelle que soit la tâche de parallélisation, le problème est partagé sur de multiples processeurs de façon à diminuer le temps de calcul. Regardons donc la façon dont se répartit la quantité de travail sur les processeurs.
Sur le CRAY, on trouve les concepts de regions parallèles, de tâche maître (un processus maître)et de tâches esclaves (de multiples processus esclaves). Supposons un programme pour lequel nous avons spécifié au compilateur qu'il devait le paralléliser (parallélisation autotâche). Nous avons pu également affiner la parallélisation par le biais de directives de compilation insérées dans le corps du programme (parallélisation macro- et microtâche). Lorsque nous lançons l'exécution du programme, nous créons un processus maître. Ce maître va créer des processus fils esclaves en préparation d'un futur travail en parallèle. La communication entre le maître et les esclaves passe par l'utilisation d'un thread. Il s'agit d'une zone mémoire utilisateur partagée également par le système d'exploitation. Elle contient principalement un Flag (Wake-Up Flag), un pointeur de contexte, et d'autres informations statistiques ou de commande. Au début du programme, tous les processus repèrent leur thread, initialisent à faux les wake-up flag et se mettent en attente. Lors de l'exécution du programme, quand on entre dans une région parallèle, le processus maître, pour demander de l'aide, active le wake-up flag . Le système d'exploitation voit ce flag et notifie le travail à faire au niveau des thread. En fonction de leur disponibilité les processeurs répondent à l'appel et viennent effectuer une partie du travail. Une fois l'intégralité du travail effectué, les esclaves retournent dans une position d'attente pour une autre région parallèle du programme. Il faut savoir que pendant l'exécution d'une région parallèle, le système d'exploitation peut avoir besoin ailleurs d'un processeur impliqué dans cette exécution. L'esclave, sur requête du système d'exploitation abandonne le programme et sauvegarde au niveau du pointeur de contexte, l'état d'avancement de son travail. Cela permet à un autre processeur de poursuivre son travail, sans avoir à attendre le retour du processeur sur ce programme.
Supposons dans un premier temps, que nous ayons, 10 itérations indépendantes à exécuter. Chacune de ces itérations nécessite un temps de 50s. Un scénario possible d'exécution est donné Fig.10.4 [22].

|
Supposons un deuxième scénario. Il nous faut effectuer 5 itérations indépendantes mais de durée 100s. Une illustration est donnée Fig.10.5 [22].

|
Lorsqu'on parle de temps d'exécution pour un programme, il faut faire la distinction
entre le temps CPU et le nombre de périodes d'horloge. En effet, le temps pendant
lequel le CPU travaille va être diminué lors de l'exécution vectorielle d'une
portion de programme. Toujours par analogie avec la chaîne de montage,
le nombre de chaise à construire étant fixé, le processeur mettra moins longtemps
pour toutes les assembler dans un mode vectoriel. Le temps pour exécuter globalement
cette portion de programme en terme de nombres de coups d'horloge diminue conjointement.
En revanche, lorsqu'on parallélise, on augmente en général le temps pendant
lequel vont travailler les différents CPUs. Non seulement ils doivent effectuer
le travail demandé dans le programme, mais ils passent du temps dans le code
supplémentaire introduit par la parallélisation (départ, fin et synchronisation
des processus). C'est parceque le travail est divisé sur ![]() processeurs
que le temps d'exécution global en termes de périodes d'horloge diminue.
processeurs
que le temps d'exécution global en termes de périodes d'horloge diminue.
Lorsqu'on parallélise, on cherche évidemment à accélérer notre processus. Le
rêve en utilisant ![]() processeurs serait d'aller
processeurs serait d'aller ![]() fois plus vite.
Ce n'est malheureusement pas le cas. Pour un problème donné, il n'existe pas
une solution informatique unique. Il existe de multiples façon d'implémenter
la solution. De plus, une fois réparti sur
fois plus vite.
Ce n'est malheureusement pas le cas. Pour un problème donné, il n'existe pas
une solution informatique unique. Il existe de multiples façon d'implémenter
la solution. De plus, une fois réparti sur ![]() processeurs, chacune de
ces versions conduit à des temps d'exécution différents. Pour caractériser le
gain lié à la parallélisation de notre programme, on définit le facteur
d'accélération (speedup)
et l'efficacité.
processeurs, chacune de
ces versions conduit à des temps d'exécution différents. Pour caractériser le
gain lié à la parallélisation de notre programme, on définit le facteur
d'accélération (speedup)
et l'efficacité.
Le facteur d'accélération ![]() est défini comme le ratio du temps d'exécution
du programme sur un processeur au temps d'exécution du même programme sur
est défini comme le ratio du temps d'exécution
du programme sur un processeur au temps d'exécution du même programme sur ![]() processeurs.
processeurs.
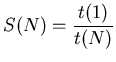

Toutefois, même si ces deux grandeurs renseignent sur la qualité de la parallélisation,
elles ne permettent en aucun cas d'apprécier la qualité de l'algorithme utilisé.
C'est pourquoi, souvent on définit une efficacité numérique qui
traduit le ratio du temps d'exécution du meilleur algorithme séquentiel au temps
utilisé par notre algorithme sur ![]() processeurs. Il est clair que cette
notion est peu objective, car elle sous-entend de connaître le meilleur
algorithme séquentiel pour résoudre notre problème. Cette notion dépend de la
taille du problème, de l'implémentation par l'utilisateur, du compilateur et
de chaque machine. En plus, le meilleur algorithme varie en fonction des avancées
dans le domaine. Cette variabilité rend mal aisé le calcul de l'efficacité numérique,
c'est pourquoi, nous chercherons uniquement à estimer la qualité de la parallélisation.
En guise d'efficacité numérique, nous donnerons les temps d'exécution de nos
programmes qui seront alors à comparer aux temps fournis dans la littérature
pour les mêmes algorithmes.
processeurs. Il est clair que cette
notion est peu objective, car elle sous-entend de connaître le meilleur
algorithme séquentiel pour résoudre notre problème. Cette notion dépend de la
taille du problème, de l'implémentation par l'utilisateur, du compilateur et
de chaque machine. En plus, le meilleur algorithme varie en fonction des avancées
dans le domaine. Cette variabilité rend mal aisé le calcul de l'efficacité numérique,
c'est pourquoi, nous chercherons uniquement à estimer la qualité de la parallélisation.
En guise d'efficacité numérique, nous donnerons les temps d'exécution de nos
programmes qui seront alors à comparer aux temps fournis dans la littérature
pour les mêmes algorithmes.
Le facteur d'accélération que l'on peut obtenir sur un algorithme peut être fortement affecté par des parties de code exécutées de manière séquentielle au sein de l'algorithme. Ces parties exécutées en séquentiel représentent un frein. Ceci est exprimé par la loi de Amdahl :

où
![]() dénotera la fraction du temps passé pour exécuter les
portions parallèles de l'algorithme9.3 et
dénotera la fraction du temps passé pour exécuter les
portions parallèles de l'algorithme9.3 et
![]() la fraction du temps qui reste séquentielle.
Par exemple, prenons une procédure contenant une region parallèle nécessitant
10000 périodes d'horloge lorsqu'elle est exécutée sur 1 processeurs. Cette procédure
a également une partie de son code qui ne peut que s'exécuter en séquentiel.
Cette partie nécessite 5000 périodes d'horloge. Dans ce cas,
la fraction du temps qui reste séquentielle.
Par exemple, prenons une procédure contenant une region parallèle nécessitant
10000 périodes d'horloge lorsqu'elle est exécutée sur 1 processeurs. Cette procédure
a également une partie de son code qui ne peut que s'exécuter en séquentiel.
Cette partie nécessite 5000 périodes d'horloge. Dans ce cas,
![]() et par conséquent:
et par conséquent:
![]() . Notons qu'il s'agit d'un facteur d'accélération,
dans le cas idéal , ou nous n'avons par d'overhead. Dans un algorithme
séquentiel structuré, nous avons déjà un overhead lié au temps d'appel
des fonctions par exemple. Mais le fait d'effectuer l'algorithme sur de multiples
processeurs va augmenter cet overhead. La loi de Amdhal énoncée se place
déjà dans le cas idéal sans overhead mais sous entend de plus:
. Notons qu'il s'agit d'un facteur d'accélération,
dans le cas idéal , ou nous n'avons par d'overhead. Dans un algorithme
séquentiel structuré, nous avons déjà un overhead lié au temps d'appel
des fonctions par exemple. Mais le fait d'effectuer l'algorithme sur de multiples
processeurs va augmenter cet overhead. La loi de Amdhal énoncée se place
déjà dans le cas idéal sans overhead mais sous entend de plus:

