Nous venons d'établir totalement la fonctionnelle
![]() à minimiser
pour reconstruire une image partant de ses projections. Il s'agit maintenant
de choisir un algorithme pour effectuer cette minimisation. Là encore, le choix
est vaste. Rappelons cette contrainte: nous voulons minimiser la fonctionnelle
à minimiser
pour reconstruire une image partant de ses projections. Il s'agit maintenant
de choisir un algorithme pour effectuer cette minimisation. Là encore, le choix
est vaste. Rappelons cette contrainte: nous voulons minimiser la fonctionnelle
![]() par l'utilisation d'un algorithme déterministe. Cela nous a déjà
permis de réduire le choix de la fonction de potentiel. Si nous souhaitons utiliser
un tel algorithme, c'est surtout du fait de sa rapidité d'exécution par rapport
aux algorithmes stochastiques.
par l'utilisation d'un algorithme déterministe. Cela nous a déjà
permis de réduire le choix de la fonction de potentiel. Si nous souhaitons utiliser
un tel algorithme, c'est surtout du fait de sa rapidité d'exécution par rapport
aux algorithmes stochastiques.
Nous laissons donc de côté les algorithmes de recuit simulé (échantillonneur de Gibbs par exemple [38]). Les méthodes stochastiques sont lourdes, car elles nécessitent de nombreux tirages aléatoires. Besag propose une version déterministe de ces méthodes de recuit simulé par une réactualisation locale des sites (ICM pour Iterated Conditional Mode), mal adaptée à notre cas. Nous envisageons donc pour minimiser notre fonctionnelle une méthode de descente.
Rappelons d'abord que le choix que nous avons fait sur la fonction de potentiel,
nous a permis de construire un critère
![]() étendu pour
la régularisation. De ce choix découle le critère MAP que nous envisageons de
minimiser:
étendu pour
la régularisation. De ce choix découle le critère MAP que nous envisageons de
minimiser:

Dans un contexte de régularisation semi-quadratique, et pour une fonction de
potentiel vérifiant les conditions Eq.9.6, la première
étape du processus itéré ne pose pas de problème. En effet, nous avons une expression
littérale des discontinuités lorsque
![]() est fixé (Par.9.2.4.5.
et Eq.9.7.):
est fixé (Par.9.2.4.5.
et Eq.9.7.):

Pour la deuxième étape, lorsque
![]() est fixé, le critère devient quadratique
en
est fixé, le critère devient quadratique
en
![]() et peut être minimisé par des méthodes classiques d'algèbre linéaire.
Il reste à en choisir une !
et peut être minimisé par des méthodes classiques d'algèbre linéaire.
Il reste à en choisir une !
Nous voulons minimiser la fonctionnelle
![]() alors que les discontinuités
alors que les discontinuités
![]() sont fixées. Plaçons nous, pour commencer, dans le cas d'un critère
d'attache aux données le plus général possible basé sur la distance de Mahalanobis,
nous avons:
sont fixées. Plaçons nous, pour commencer, dans le cas d'un critère
d'attache aux données le plus général possible basé sur la distance de Mahalanobis,
nous avons:

La matrice
![]() est une matrice carrée de dimension
est une matrice carrée de dimension ![]() ,
,
![]() et
et
![]() sont des vecteurs de dimensions
sont des vecteurs de dimensions ![]() .
Pour une image standard en TEP, nous avons
.
Pour une image standard en TEP, nous avons
![]() voxels. La matrice
voxels. La matrice
![]() est donc de dimensions impressionnantes
puisqu'elle compte quelque
est donc de dimensions impressionnantes
puisqu'elle compte quelque ![]() termes. Même avec un CRAY à sa disposition,
l'inversion directe de la matrice par une méthode de type factorisation SVD
ou QR est donc compromise. En 2D, ce type de méthode a pu être envisagé [85,13,56].
Mais les puissances de calculs disponibles actuellement ferment la route à ce
type de méthode dans un cas tridimensionnel (surtout si on conserve les matrices
dans leur intégralité, ce que l'on fait rarement en pratique puisque la matrice
est très creuse). On va donc utiliser une méthode itérative de résolution qui
va construire une série d'images
termes. Même avec un CRAY à sa disposition,
l'inversion directe de la matrice par une méthode de type factorisation SVD
ou QR est donc compromise. En 2D, ce type de méthode a pu être envisagé [85,13,56].
Mais les puissances de calculs disponibles actuellement ferment la route à ce
type de méthode dans un cas tridimensionnel (surtout si on conserve les matrices
dans leur intégralité, ce que l'on fait rarement en pratique puisque la matrice
est très creuse). On va donc utiliser une méthode itérative de résolution qui
va construire une série d'images
![]() telles que:
telles que:
Il faut dire que même pour un minimum global, la solution obtenue ne sera pas forcément conforme à ce que nous attendons réellement! En effet bien des fois la solution mathématique n'est pas la réponse pertinente!
Les méthodes itératives constituant encore un ensemble trop vaste, on se restreint aux seules méthodes dites de descente. Et même au sein de ces méthodes de descente, seule la méthode de gradient conjugué est envisagée. Notre choix a été guidé par l'étude comparative de nombreuses méthodes itératives de reconstruction effectuée par Koulibaly [52]. Nous laissons donc de coté: les méthodes de type Gauss-Seidel ou de sur-relaxations successives (SOR pour Successiv Over Relaxation) [79], les méthodes ILST (Iterativ Least Square Solution) [92], ART (Algebraic Reconstruction Technic) [43], les méthodes de descente par plus grande pente (steepest descent), la méthode de Newton ou Quasi-Newton.
Supposons que nous partions d'une estimée initiale de notre image
![]() (vecteur de dimension
(vecteur de dimension ![]() ) et dans cet espace de dimension
) et dans cet espace de dimension ![]() ,
nous fixons une direction de descente
,
nous fixons une direction de descente
![]() (vecteur de dimension
(vecteur de dimension
![]() ). Alors toute fonction
). Alors toute fonction
![]() construite sur
construite sur
![]() peut être minimisée suivant cette direction. On peut donc rêver qu'une succession
de minimisation suivant des directions différentes va nous conduire à notre
minimum. Les différentes méthodes de descente vont donc différer sur la façon
dont les directions successives de minimisation sont choisies et sur la façon
dont le minimum est choisi suivant chaque direction. Supposons que nous ayons
choisi une méthode pour minimiser suivant une direction, alors une itération
peut se résumer comme ceci:
peut être minimisée suivant cette direction. On peut donc rêver qu'une succession
de minimisation suivant des directions différentes va nous conduire à notre
minimum. Les différentes méthodes de descente vont donc différer sur la façon
dont les directions successives de minimisation sont choisies et sur la façon
dont le minimum est choisi suivant chaque direction. Supposons que nous ayons
choisi une méthode pour minimiser suivant une direction, alors une itération
peut se résumer comme ceci:
Partant d'une image
![]() et d'une direction
et d'une direction
![]() ,
pour la fonction
,
pour la fonction ![]() , il faut trouver le scalaire
, il faut trouver le scalaire ![]() (pas
de descente) qui minimise
(pas
de descente) qui minimise
![]() On remplace
On remplace
![]() par
par
![]() On change de direction
On change de direction
![]() et on recommence.
et on recommence.
Si nous définissons la fonction
![]() ,
en cherchant son minimum (
,
en cherchant son minimum (
![]() ),
nous retombons sur le système linéaire (Eq.9.9). Autrement dit,
résoudre le système Eq.9.9 est équivalent à minimiser la fonction
),
nous retombons sur le système linéaire (Eq.9.9). Autrement dit,
résoudre le système Eq.9.9 est équivalent à minimiser la fonction
![]() .
.
Notre résolution est itérative, au bout de ![]() itérations, nous
avons déterminé
itérations, nous
avons déterminé ![]() directions de projections
directions de projections
![]() ,
l'image à laquelle nous sommes parvenus est donc:
,
l'image à laquelle nous sommes parvenus est donc:
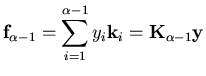

Il nous reste maintenant à définir comment choisir à chaque itération la direction
de descente optimale. On peut montrer [40] qu'une solution optimale
visant à réduire le résidu consiste à choisir la direction de descente
![]() qui s'appuie sur la direction de descente précédente
qui s'appuie sur la direction de descente précédente
![]() et sur le résidu de l'itération
et sur le résidu de l'itération
![]() . Plus précisément:
. Plus précisément:

En mettant tous ces éléments bout à bout, on arrive à l'algorithme de Gradient
conjugué utilisé qui conserve l'esprit de l'algorithme tel qu'il est décrit
par Hestenes et Stiefel [44,40].

En regroupant l'algorithme de minimisation alternée (Alg.4)
d'une part et l'algorithme de gradient conjugué (Alg.5)
d'autre part, nous aboutissons à la méthode de reconstruction algébrique implémentée.
Elle est illustrée Alg.6


